大语言模型(LLM)作为人工智能领域的核心技术,通过海量文本数据训练已具备强大的语言理解和生成能力。其核心目标在于模拟人类语言的深层规律,实现自然流畅的文本交互。这类模型通常基于Transformer架构,利用自注意力机制捕捉长距离语义依赖,显著提升了文本处理任务的性能表现。
本文发表于《自然》子刊《npj
Digital
Medicine》(JCR与中科院双一区,IF=15.2),标题为《通过多智能体对话增强大语言模型的临床诊断能力》。研究团队由四川大学华西医院与多家机构联合组成,开发了一种基于多智能体对话框架(MAC)的疾病诊断系统。该框架受临床多学科团队(MDT)协作模式的启发,通过模拟医生群体的集体智慧,显著提升了大语言模型在复杂医疗场景中的应用效能。
研究团队从Orphanet数据库精选302种罕见病病例构建测试集,系统评估了GPT-3.5、GPT-4及MAC框架的诊断性能。结果表明,MAC框架在诊断准确率、检查建议合理性等方面均优于单一模型,为AI医疗的临床转化提供了新的技术路径。
摘要
大型语言模型
(LLM) 在医疗保健任务中显示出前景,但在复杂的医疗场景中面临挑战。我们开发了一个用于疾病诊断的多代理对话 (MAC)
框架,受到临床多学科团队讨论的启发。使用 302 例罕见病病例,我们评估了 GPT-3.5 、 GPT-4 和 MAC
对医学知识和临床推理的影响。MAC 在初次和随访咨询中均优于单一模型,在诊断和建议测试方面取得了更高的准确性。使用 GPT-4
作为基本模型,四个医生代理和一个监督代理实现了最佳性能。MAC 在重复运行中表现出高度一致性。进一步的比较分析表明,MAC
的性能也优于其他方法,包括 Chain of Thoughts (CoT)、Self-Refine 和
Self-Consistency,具有更高的性能和更多的输出标记。该框架显著提高了 LLM
的诊断能力,有效地衔接了理论知识和实际临床应用。我们的研究结果强调了多代理 LLM 在医疗保健中的潜力,并建议对其临床实施进行进一步研究。
背景
提到大型语言模型(LLM),人们很容易联想到曾经火爆的ChatGPT。这一技术凭借海量文本训练,展现出强大的语言能力,无论是写诗、编代码还是应对医学考试都不在话下。然而,当将其应用于实际医疗场景时,问题便暴露出来。在罕见病诊断中,GPT-4虽能详细列举疾病特征,但面对发热究竟是普通感冒还是红斑狼疮引起这样的基础诊断问题,却时常出现偏差。这种“理论知识丰富却难以解决实际问题”的现象,正是本研究开展的初衷。
本研究提出一种新的医疗诊断框架,通过模拟临床多学科会诊模式,显著提升了大型语言模型在复杂医疗场景中的诊断表现。研究团队选取302种罕见病临床案例,对GPT-3.5、GPT-4及新开发的多智能体对话框架进行系统性评估,深入探究人工智能在医学推理领域的潜力与面临的挑战。
研究的起点源于大型语言模型在医疗应用中的核心矛盾:尽管拥有庞大的医学知识库,但在真实临床环境中,模型常表现出理论与实践脱节的情况。例如,在罕见病诊断中,GPT-4虽能精准描述疾病特征,却难以从零散的临床症状中得出正确结论。这种“知识充沛却应用乏力”的现象,促使研究者借鉴多学科团队(MDT)的协作模式,设计出包含医生智能体与监督智能体的对话框架。
多智能体对话框架的设计灵感来自临床多学科团队协作模式,由管理员、监督员及4名医生构成动态交互网络,共同模拟真实医疗场景中的多角色协作。管理员负责将非结构化病历转化为结构化数据模板;监督员则引导讨论方向,利用医学知识图谱实时验证诊断逻辑;医生则从不同专科视角进行分析,形成差异化的推理路径。
研究方法
实验采用双盲交叉验证机制,从Orphanet数据库筛选302种罕见病构建测试集。评估分为两阶段:初级咨询模拟首诊场景,仅提供症状与基础检查信息;后续咨询模拟多学科会诊场景,补充影像学与基因检测结果。性能评估采用诊断准确性、临床效用及推理透明度三维度指标体系。为排除模型幻觉干扰,所有输出均需通过基于规则的事实核查模块验证。
研究结果
研究结果表明,GPT-3.5、GPT-4和多智能体对话框架虽均有一定知识水平,但前两者的诊断结果在实际病例中表现较差,凸显了知识应用与实践的差距。与单智能体模型相比,多智能体对话框架显著增强了语言模型的诊断能力。
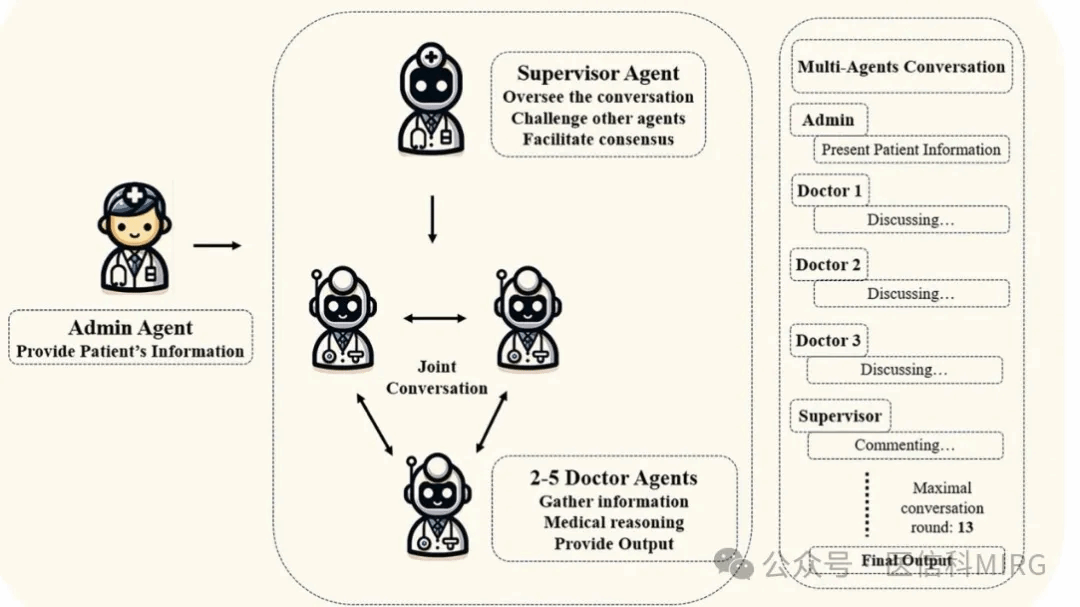
本研究成功搭建了连接医学知识与临床实践的桥梁。通过模拟医生协作认知过程,多智能体对话框架证明了其在复杂推理任务中的优越性,开创了语言模型在医疗领域的新应用模式。未来的发展方向可能包括构建多模态诊断系统、建立动态知识更新机制以及优化智能体思维模式等,以推动人工智能向“临床伙伴”转变,实现提升医疗质量与公平性的目标。
本研究证实了多智能体系统在复杂医疗推理中的独特价值。通过模拟医生协作认知过程,该系统实现了知识应用效率和决策可解释性的突破。但研究也揭示了当前技术的局限性,如对非结构化病历的解析准确率有待提高,部分诊断建议存在过度治疗或隐私风险,凸显了人机协同的必要性。
回顾
回顾本次研究,最大的突破或许并非技术本身,而是验证了“三个臭皮匠赛过诸葛亮”的智慧。当人工智能学会像人类一样协作,医疗诊断开始有了温度。下一步,我们计划为该系统整合CT影像识别与语音病历分析功能,打造真正的多模态AI医生,为医疗领域带来更深远的影响。
MIRG
AI-Research Group
川北医学院口腔科创平台×医学信息科研课题组是一个创立于2022年的新兴平台,
本课题组是计算机应用协会的一个独立部门, 旨在训练本科生自主科研协作能力的科研课题组,致力于数字医学,战争医学,公共卫生领域的研究,
本团队积极开展国际合作, 让AI成为照进现实的普罗米修斯之火!
外部链接
初审初校:宁芷琪 杜一冰 罗子甯
复审复校:彭嘉宽
终审终校:刘英


